
La inteligencia artificial puede mejorar la investigación sobre la química de la sal de fundición nuclear fundiendo de manera rápida y eficiente los resultados experimentales y, en última instancia, reduciendo el tiempo y los costos asociados con los métodos experimentales tradicionales.
Imagine entrar en el laboratorio y conocer los resultados del experimento antes de intentarlo. ¿Qué pasa con los resultados de los 100 experimentos? ¿mil? ¿Cómo afectará sus decisiones al desarrollar su producto? La mayoría de nosotros estamos familiarizados con la capacidad de AI (AI) para generar fotos, videos y chats de texto realistas, pero podemos aprovechar este poder de otras maneras. Generando nuevos resultados experimentales.
Esta potencia predictiva es ampliamente aceptada en campos, como los productos farmacéuticos y la investigación de la batería, pero los avances en la química de sales fundidas nucleares aún presentan una oportunidad importante para la integración de la IA. Los experimentos electroquímicos de sales fundidas tienden a llevar mucho tiempo y costosos, requieren múltiples equipos costosos y requieren un amplio conocimiento para funcionar con precisión. Ahora, imagine la inversión necesaria para probar cientos o miles de composiciones y elementos de sal diferentes.
Aquí es donde interviene la IA. Utilizando datos experimentales pasados, se pueden desarrollar modelos de IA que pueden predecir rápidamente diferentes respuestas electroquímicas para una variedad de configuraciones experimentales. ¿Y la mejor parte? Una vez que el modelo ha sido entrenado y validado, la respuesta se puede generar en segundos en lugar de días. Esto proporciona una forma conveniente para que los investigadores estimen innumerables resultados antes de comprometerse con una inversión crítica en experimentos físicos, lo que lleva a opciones experimentales más informadas y eficientes.

El motor detrás de la predicción
Para tener confianza en sus predicciones, debe comprender exactamente cómo se generan estas predicciones. Aunque el aprendizaje automático es un campo vasto, sus enfoques generalmente se pueden dividir en tres tipos diferentes: supervisor, sin supervisión y aprendizaje de refuerzo. La investigación actual que se lleva a cabo es un aprendizaje muy monitoreado, pero cada método es ligeramente diferente, por lo que es importante conocer esta distinción. Debido al aprendizaje monitoreado, las entradas, también conocidas como características, están etiquetadas y vienen con objetivos. Esto es lo que estás tratando de predecir. Durante el entrenamiento, la red monitoreada generalmente sigue cuatro pasos específicos:
Propagación de reenvío: mueve los datos a través del modelo y devuelve la salida predicha. A veces también se llama un «pase hacia adelante». Cálculo de pérdidas: compare los resultados de la predicción del pase hacia adelante con los resultados reales. Los errores medios cuadrados se usan comúnmente para el aprendizaje monitoreado. Backpropagation: calcula la pendiente de error de la función de pérdida para determinar qué parámetros deben ajustarse. Optimización: actualice los parámetros internos para minimizar las pérdidas totales a través de algoritmos como Adam y el descenso de gradiente.
Estos cuatro pasos se repiten, y cada iteración se llama una época. Dados los tiempos adecuados, los datos de capacitación de calidad y los buenos modelos, la dinámica del sistema está muy bien aproximada. Este enfoque crea modelos basados en datos que difieren de los modelos tradicionales basados en la física, ya que aprenden a aproximar los comportamientos físicos puramente subyacentes de los datos históricos, en lugar de las simulaciones de ecuaciones de física. Por ejemplo, la Figura 1 muestra las respuestas verdaderas y predichas de voltamograma circular de redes neuronales capacitadas en 4% con datos de sal fundidos LiCl-KCl a 798 K.
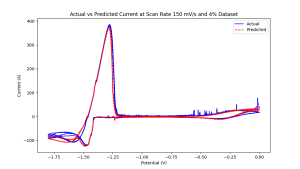
4% en peso de uranio en 798 k Licl-KCl Salt fundido
El núcleo del aprendizaje monitoreado es un proceso de cuatro pasos, y hay muchas formas de implementar esto. La forma más fácil es a través de una red Perceptron de múltiples capas (MLP). Aquí, la información fluye de un lado a otro en una dirección, siendo la salida final la predicción real. Los casos más complejos ocurren con datos secuenciales o de series de tiempo, con redes neuronales recurrentes (RNN) a menudo brillantes.
A diferencia de MLP, estas redes pueden retroceder la información a sí misma, procesar secuencias de datos y «recordar» lo que sucedió anteriormente. Esto lo hace ideal para tareas donde el orden de información es importante. Las arquitecturas comunes incluyen RNN simples, redes neuronales de memoria a largo plazo a largo plazo (LSTM) y la unidad de regeneración de la puerta redes neuronales (Grus). Las opciones arquitectónicas están determinadas principalmente por el tipo de datos que se procesan y los objetivos reales del proyecto en sí.
Cómo la teoría de la práctica de las vCus
En VCU, nuestro equipo está adoptando activamente este enfoque impulsado por la IA, aprovechando poderosos recursos computacionales y bibliotecas de codificación avanzadas para desarrollar y capacitar a múltiples modelos de redes neuronales con datos experimentales reales. Sin embargo, un obstáculo importante en este campo especializado es la rareza inherente de los datos electroquímicos de alta calidad. Esto condujo a diseñar partes clave de la investigación. Decidimos investigar cómo los modelos pueden aprender y generalizar efectivamente desde un conjunto de datos limitado.
Para investigar esto, capacitamos múltiples redes neuronales de diferentes arquitecturas utilizando datos experimentales históricos de diferentes configuraciones experimentales. Estos datos diversos se utilizan para entrenar múltiples arquitecturas de redes neuronales con diferentes tamaños de conjuntos de datos, lo que le permite determinar los datos mínimos necesarios para producir resultados confiables, así como qué modelos funcionan de manera óptima con información rara. Además, desafiamos las redes con entradas incompletas para ver si se podrían generar respuestas electroquímicas precisas a partir de información no ideal. Los resultados iniciales mostraron constantemente que las redes neuronales pueden aproximar mejor las respuestas electroquímicas, incluso con datos más limitados o incompletos.
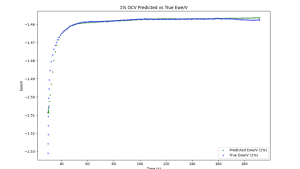
Según estos hallazgos iniciales, se realizaron simulaciones electroquímicas integrales de UCL3 a dos concentraciones de peso diferentes, y se desplegaron varios modelos de IA diferentes para predecir el rango completo de respuestas electroquímicas. Las pruebas iniciales proporcionaron excelentes resultados tanto para la voltametría periódica como para los datos de potencial de circuito abierto. La Figura 2 muestra un ejemplo de el 1% de UCL3 en la sal fundida LiCl-KCl, que muestra cuán precisamente el modelo puede aproximar estas respuestas electroquímicas.
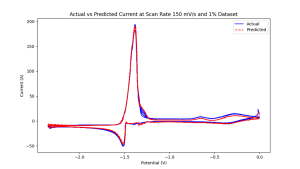
748 K LIC -KCL Salt fundida
A pesar de este éxito en la voltametría cíclica y las posibilidades de circuito abierto, otra técnica electroquímica importante, la espectroscopía de impedancia electroquímica, aún presenta varios desafíos. La Figura 3 ilustra este punto mostrando una trama Nyquist generada verdadera al mostrar una coincidencia no ideal entre los datos predichos y reales.
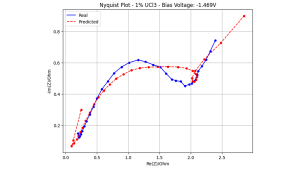
Datos espectroscópicos de 1% en peso de uranio en sales fundidas LiCL-KCL a 748 K.
Abra el camino hacia la innovación futura
Ha habido bastante progreso, pero todavía hay mucho que hacer. Nuestros modelos de IA muestran una inmensa promesa al predecir la respuesta de muchas tecnologías electroquímicas, como la voltametría periódica y las posibilidades de circuito abierto, pero otras áreas siguen siendo fronteras activas. La espectroscopía de impedancia electroquímica presenta un desafío importante debido a sus reacciones complejas dependientes de la frecuencia. Las predicciones de aprendizaje requieren modelado más sofisticado y datos de entrenamiento de alta calidad extensos. Al expandir las capacidades de predicción con esta amplia gama de métodos, el objetivo es reducir aún más la necesidad de experimentos de física costosos y que requieren mucho tiempo, lo que permite a los investigadores explorar vastas espacios de parámetros digitales.
En el futuro, nos gustaría extender esta función de predicción a un rango más allá de un solo sistema elemental de sal fundida. Al abordar la complejidad de las sales fundidas multicomponentes, podemos desbloquear una comprensión más completa de las interacciones complejas que ocurren dentro de estos sistemas críticos y extraer importantes parámetros del sistema, como la termodinámica y las propiedades de transporte.
Además, nos gustaría extender este poder predictivo hacia otras tecnologías importantes, como la espectroscopía de descomposición inducida por láser. Este método tiene una promesa inconmensurable en el mundo de las sales fundidas nucleares y es un objetivo importante para la integración de IA porque puede proporcionar información rápida sobre la composición elemental.
En última instancia, nuestro trabajo intenta acelerar drásticamente nuestra comprensión y desarrollo fundamental de la tecnología de sal fundida, aplicando a los investigadores a identificar de manera rápida y eficiente los experimentos más influyentes y acelerar las aplicaciones del mundo real.
referencia
A. Zhang et al. , Buce en Deep Learning, Cambridge University Press (2023). S. Rakhshan Pouri, «Estudio comparativo de modelos de difusión y neurointeligencia artificial con respecto a los procesos electroquímicos de disolución U y Zr en sales compartidas LiCl-KCl», https://doi.org/10.25772/60s6-ty60. TP Lillicrap et al. , «Backpropagation and the Brain», Nat Rev Neurosci 21 6, 335, Nature Publishing Group (2020); https://doi.org/10.1038/s41583-020-0277-3.
Este artículo también se presentará en la 23a edición de trimestralmente Publicación.
Source link